TODO . (NOT YET)
classify >J48>Cross Validation
=== Run information ===
Scheme:weka.classifiers.trees.J48 -C 0.25 -M 2
Relation: iris
Instances: 150
Attributes: 5
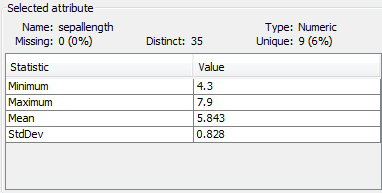
sepallength
sepalwidth
petallength
petalwidth
class
Test mode:10-fold cross-validation
=== Classifier model (full training set) ===
J48 pruned tree
------------------
petalwidth <= 0.6: Iris-setosa (50.0)
petalwidth > 0.6
| petalwidth <= 1.7
| | petallength <= 4.9: Iris-versicolor (48.0/1.0)
| | petallength > 4.9
| | | petalwidth <= 1.5: Iris-virginica (3.0)
| | | petalwidth > 1.5: Iris-versicolor (3.0/1.0)
| petalwidth > 1.7: Iris-virginica (46.0/1.0)
Number of Leaves : 5
Size of the tree : 9
Time taken to build model: 0.04 seconds
=== Stratified cross-validation ===
=== Summary ===
Correctly Classified Instances 144 96 %
Incorrectly Classified Instances 6 4 %
Kappa statistic 0.94
Mean absolute error 0.035
Root mean squared error 0.1586
Relative absolute error 7.8705 %
Root relative squared error 33.6353 %
Total Number of Instances 150
=== Detailed Accuracy By Class ===
TP Rate FP Rate Precision Recall F-Measure ROC Area Class
0.98 0 1 0.98 0.99 0.99 Iris-setosa
0.94 0.03 0.94 0.94 0.94 0.952 Iris-versicolor
0.96 0.03 0.941 0.96 0.95 0.961 Iris-virginica
Weighted Avg. 0.96 0.02 0.96 0.96 0.96 0.968
=== Confusion Matrix ===
a b c <-- classified as
49 1 0 | a = Iris-setosa
0 47 3 | b = Iris-versicolor
0 2 48 | c = Iris-virginica
-if confidence Factor discreased , We have
=== Confusion Matrix ===
a b c <-- classified as
49 1 0 | a = Iris-setosa
0 46 4 | b = Iris-versicolor
0 4 46 | c = Iris-virginica
==>if confidence Factor discreases Error numbers increases
20.png
a b c <-- classified as
15 0 0 | a = Iris-setosa
0 19 0 | b = Iris-versicolor
0 2 15 | c = Iris-virginica
=========
kmeans
1)with 2 clusters:
=== Run information ===
Scheme:weka.clusterers.SimpleKMeans -N 2 -A "weka.core.EuclideanDistance -R first-last" -I 500 -S 10
Relation: iris
Instances: 150
Attributes: 5
sepallength
sepalwidth
petallength
petalwidth
class
Test mode:evaluate on training data
=== Model and evaluation on training set ===
kMeans
======
Number of iterations: 7
Within cluster sum of squared errors: 62.1436882815797
Missing values globally replaced with mean/mode
Cluster centroids:
Cluster#
Attribute Full Data 0 1
(150) (100) (50)
==================================================================
sepallength 5.8433 6.262 5.006
sepalwidth 3.054 2.872 3.418
petallength 3.7587 4.906 1.464
petalwidth 1.1987 1.676 0.244
class Iris-setosa Iris-versicolor Iris-setosa
Time taken to build model (full training data) : 0.03 seconds
=== Model and evaluation on training set ===
Clustered Instances
0 100 ( 67%)
1 50 ( 33%)
2)With 3 clusters:
=== Run information ===
Scheme:weka.clusterers.SimpleKMeans -N 3 -A "weka.core.EuclideanDistance -R first-last" -I 500 -S 10
Relation: iris
Instances: 150
Attributes: 5
sepallength
sepalwidth
petallength
petalwidth
class
Test mode:evaluate on training data
=== Model and evaluation on training set ===
kMeans
======
Number of iterations: 3
Within cluster sum of squared errors: 7.817456892309574
Missing values globally replaced with mean/mode
Cluster centroids:
Cluster#
Attribute Full Data 0 1 2
(150) (50) (50) (50)
==================================================================================
sepallength 5.8433 5.936 5.006 6.588
sepalwidth 3.054 2.77 3.418 2.974
petallength 3.7587 4.26 1.464 5.552
petalwidth 1.1987 1.326 0.244 2.026
class Iris-setosa Iris-versicolor Iris-setosa Iris-virginica
Time taken to build model (full training data) : 0.01 seconds
=== Model and evaluation on training set ===
Clustered Instances
0 50 ( 33%)
1 50 ( 33%)
2 50 ( 33%)
==============
Wich Attributs for better Classification in kmeans ?
=> petallength(inter/ intra Class)
28_intraInter_patellength.png
=> petallewidth(inter/ intra Class)
29_intraInter_patellength.png